
被《经验时代》刷屏之后,剑桥博士长文讲述RL破局之路
被《经验时代》刷屏之后,剑桥博士长文讲述RL破局之路RL + LLM 升级之路的四层阶梯。
来自主题: AI技术研报
9121 点击 2025-04-24 18:21
 搜索
搜索
RL + LLM 升级之路的四层阶梯。
论文的第一作者是香港中文大学(深圳)数据科学学院三年级博士生徐俊杰龙,指导老师为香港中文大学(深圳)数据科学学院的贺品嘉教授和微软主管研究员何世林博士。贺品嘉老师团队的研究重点是软件工程、LLM for DevOps、大模型安全。
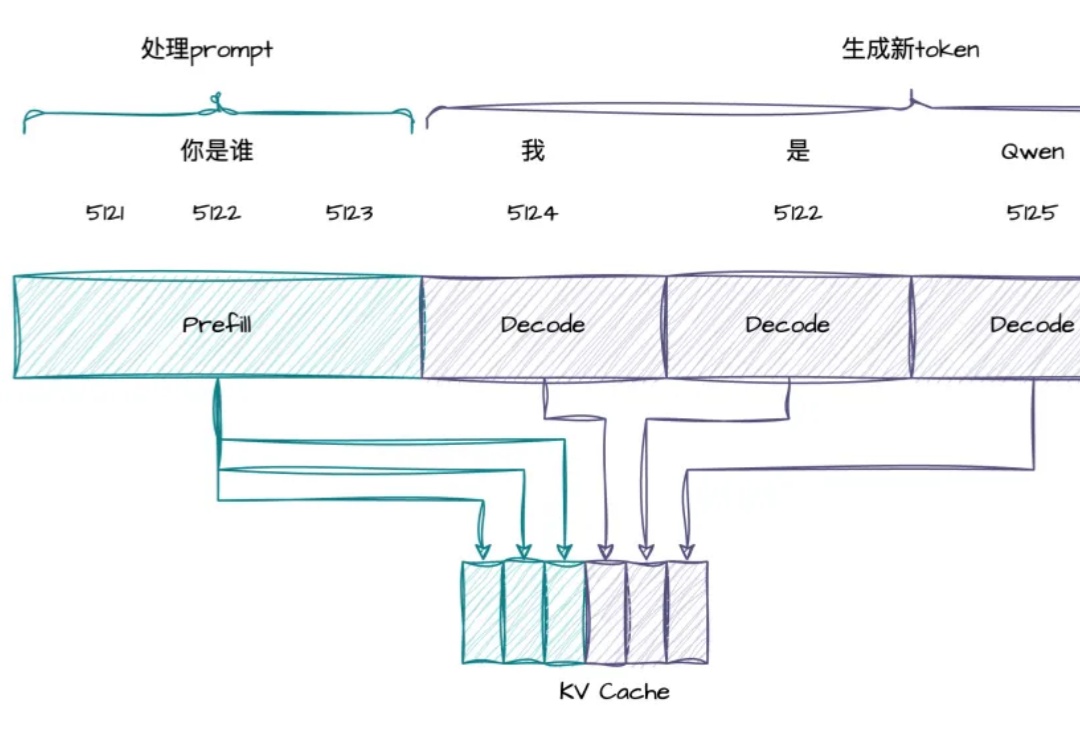
RTP-LLM 是阿里巴巴大模型预测团队开发的高性能 LLM 推理加速引擎。它在阿里巴巴集团内广泛应用,支撑着淘宝、天猫、高德、饿了么等核心业务部门的大模型推理需求。在 RTP-LLM 上,我们实现了一个通用的投机采样框架,支持多种投机采样方法,能够帮助业务有效降低推理延迟以及提升吞吐。

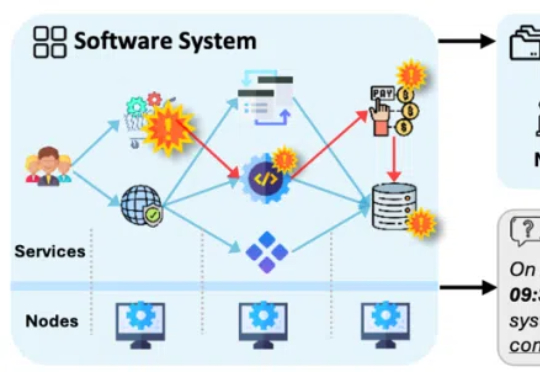
LLM Agent 火了两年了,但业界仍然存在许多非共识。智能体数量卷上去了,概念炒上去了,但质量参差不齐,娱乐向的不好玩,提效向的不好用,具体企业落地更是各种大小问题不断。

在人工智能飞速发展的今天,LLM 的能力令人叹为观止,但其局限性也日益凸显 —— 它们往往被困于训练数据的「孤岛」,无法直接触及实时信息或外部工具。

2025年,人工智能领域正在经历一场由LLM Agent引发的深刻变革,不管普通人的衣食住行还是研究者的尖端研究,都很难不受Agent的影响。

强化学习提升了 LLM 各方面的能力,而强化学习本身也在进化。
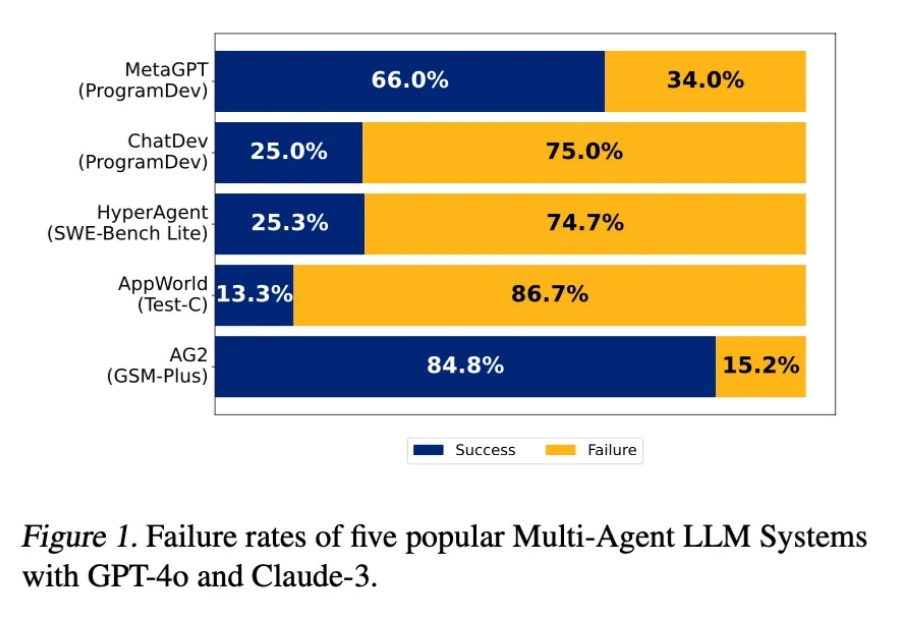
这两年,AI 领域最激动人心的进展莫过于大型语言模型(LLM)的崛起,LLM 展现了惊人的理解和生成能力。
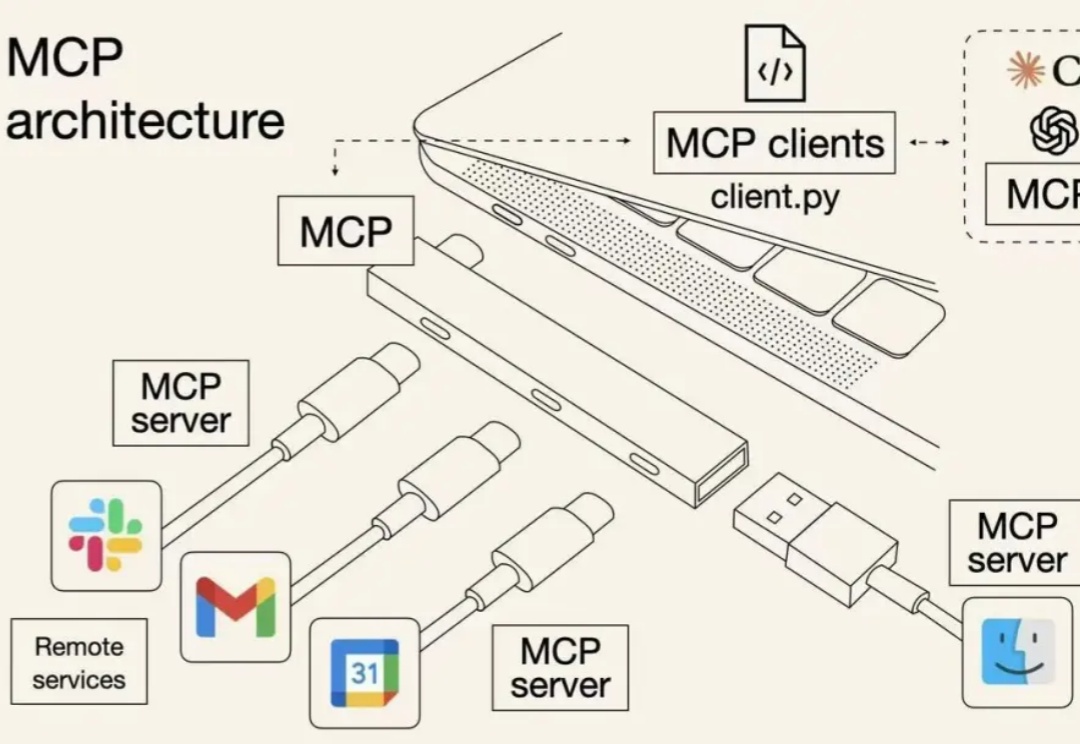
在拾象团队的 2025 的 AI 关键预测中,我们提到:随着 Agent 时代到来,OS 才是 LLM 厂商们最高的护城河,从 computer use 到 MCP,Anthropic 构建 OS 的决心是 AI labs 中最强、最明显的。

清华智能产业研究院(AIR)博三在读,去年六月份,出于对语言模型 LLM 的强烈兴趣,加入了字节 as Top Seed Intern,在人工智能的最前沿进行探索。刚好这个话题和我现在做的工作强相关,我分享一下自己的观点和亲身体验。